Earlier this year I was promoted to be a staff software engineer. This involves not just problem solving, but also a (partial) responsibility for the culture of my workplace.
One of the things I struggled with for a long time – long before I was working as a full-time programmer – was a lack of understanding of how senior people were able to come up with the clever ideas they come up with. Sometimes it’s a stroke of inspiration. More often, I think, it comes from hard work. There are elements of experience and knowledge and pattern recognition, but fundamentally it is hard work.
I wanted to use this post as a way of exposing what that hard work sometimes looks like. It’s not about typing code quickly. It’s about thinking slowly, until the right answer becomes obvious.
This post is long, but the point is not the technical solution, it’s that the process was longer than it seems from the result. And that’s not only okay, that’s the only way anyone works.
Some context
I’m building a small service at work, which you might think of as kind of a cut-price Sentry.1 Specifically, by invoking one line of code you can record a PHP stack trace at that location; and you can do so in a manner that ensures only one copy of each unique trace is stored. With a high volume of requests (thousands per second) this is far more economical than using our logging pipeline.
This is a system with very high write volume (up to once per request), but a very low read volume (it will only be consumed by developers). We’re extremely tolerant to write failures, as you might expect, or even total data loss. The volume of persistent data is likely to be hundreds of megabytes to single digit gigabytes.
The storage backend we settled on was Redis, for a range of reasons both technical and organizational.
I have been working on spinning up the service and having it record data. Until
today, I didn’t give much thought to the structure of the data consumer. We want
something a bit nicer than using telnet as a Redis client, and I’d originally
thought I’d whip up a little mini-app, integrated into our back office systems.
A few suggestions
As part of the architecture review process2 I got a number of comments, but for our purposes today I just want to highlight one of them.
That suggestion is that rather than writing a frontend for querying this data, I could instead use Google BigQuery. This was a great suggestion, because it meant I could focus on the bits I enjoy and am good at, instead of building and supporting a user interface. It also enables new uses of the data without more code being written. Great!
So now the project has shifted a bit. It will still be exactly what I thought, but we need to get the data into BigQuery.
Something I did today
Today I decided I should figure out how we would get the data into BigQuery. I’m tempted to fully set out the constraints here, but that would spoil the ending. Instead, I’ll try to take you through my thinking process.
I started by reading through the BigQuery documentation, to see what sort of limits I was likely to face there. BigQuery is designed as a column-oriented analytic data store for huge volumes of data that occasionally changes. The normal workload for this system would involve occasionally loading large immutable datasets – probably terrabytes of new rows loaded once a day, with no updates.
But my dataset is small, so maybe I could manipulate the system a bit.
My first natural instinct was to see whether we could use BigQuery as a backing store without Redis. I was pretty sure this was a terrible idea, and I was right. BigQuery tables are limited to 1,000 updates a day; we need thousands of updates a second.
Still, we could regularly push batches of data to BigQuery. Once every two minutes would be 720 updates a day. That gives us some headroom for an occasional manual change.
But what would the batches be? We need to have some idea of the state of what is
in BigQuery to know what needs to be updated. We could use MERGE queries, but
these are expensive and not best practice. And anyway, I’d still have to run a
SCAN across the entire Redis store to get the state of the world. It seems
wasteful and difficult to try to merge the two.
So another idea: I can just re-load the whole dataset every few minutes. That
process is pretty simple: I do a SCAN, dump the data out to JSON (one record
per line), and trigger a load into BigQuery. I’m allowed to do that pretty
often; it can be done without impacting write availability of Redis; and to boot
data loads into BigQuery are free.
My plan was to use a cron job that would do this periodic sweeping of a new copy of the data into BigQuery. This seems totally reasonable; we just need to make sure we don’t try to write two copies of the table at once. I wanted this to be relatively cloud native too, so I didn’t want to store any local state.3
So enter what seemed to be to be the simplest locking mechanism: a file in GCS. But now we’re dealing with lock files and that means race conditions, so I thought I would try to diagram it out, to ensure I wasn’t missing an edge case. When things invariably fail, I want the system to recover without difficulty.
So I opened up Lucidchart and got to diagramming.
Success!
After an hour or more, I had come up with what I thought of as the most simplified version of this system. There wre more lines crossing than I was happy about, but ultimately it seemed reasonable.
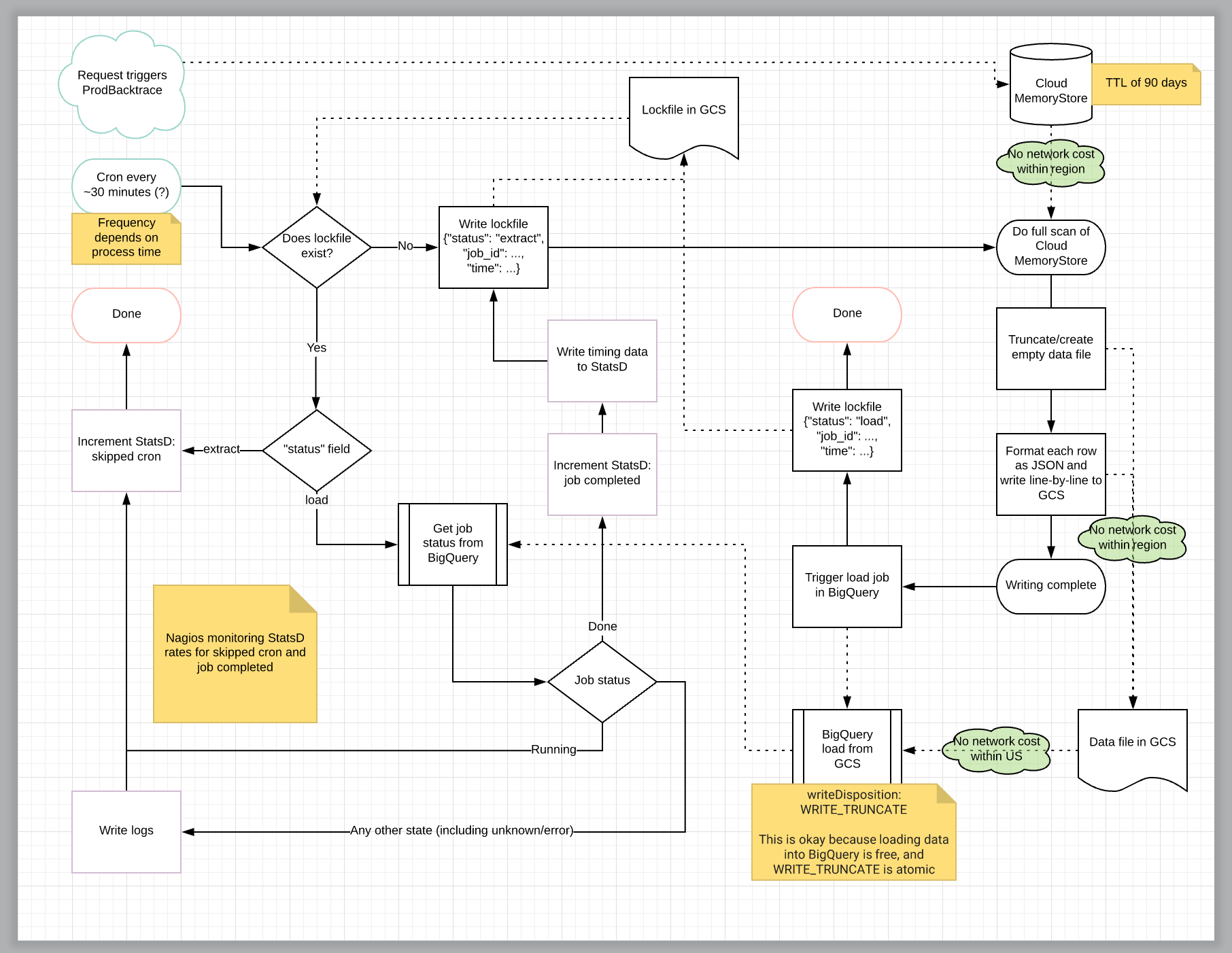
Reasonable-ish
I mean, that seems reasonable, but it has a lot of moving parts. At this point though the flowchart looks pretty nice. There aren’t many overlapping lines, and the overlapping lines are all sensible enough. We appear to have handled most of the edge cases gracefully. At this point I’ve spent about three hours on this, and honestly I’m pretty proud of myself.
But I didn’t stop there.
That’s important. That is the difference between junior-engineer me and senior-engineer me. Junior-engineer me would have stopped. I would be done. I would have shared this out, or just built it.
Today I didn’t stop there. I looked at the system I’d built, and then I went back with a critical eye. I remembered reading something in the BigQuery documentation about external data sources, including JSON in GCS. Maybe I could manage less of this process.
And it turns out that for this use case, JSON in GCS being queried by BigQuery is totally appropriate. We have to be a little cautious, but upload-and-replace in GCS is atomic (or at least can be) and the performance characteristics aren’t so bad. We lose the ability to do things like partitioning and clustering to reduce query cost, but the datasets are small enough that it doesn’t really matter.
And so I threw away two or more hours of work, and came up with this simpler version. So simple it doesn’t even need a flowchart.
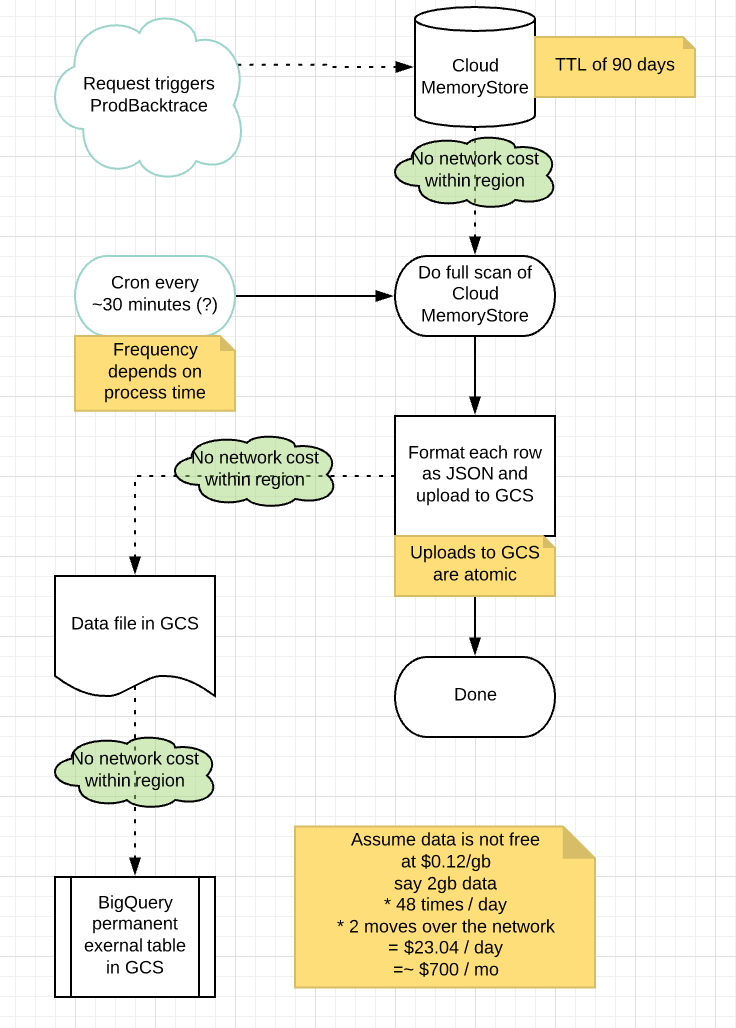
The lesson
It’s okay to throw away time. I might have felt guilty about wasting this time. That’s my instinct. I felt defensive – against myself! – of the thing I had spent a couple of hours creating. I had to work against my instincts, overcome my insecurities, to assess honestly what the better solution was.
My time is pretty expensive to my employer. A couple of hours is nothing to sneeze at. But spending that time, and then spending the extra half hour to reassess and convince myself of the obviously-better approach will pay many times that time cost in dividends. I don’t have to ask others to review this; the complexity of the code is reduced; the time to build the system is reduced by well more than two hours.
This is what it means to be a senior engineer.4 Tonight, having thrown away all this work, feeling like I wasted that time, I actually feel more comfortable with my title than I have perhaps ever before.
- It is significantly different in meaningful ways that aren’t important here, but in this case Sentry isn’t a better option. [return]
- A process by which interested folks can comment on a proposal, with a particular eye to the soundness of the approach. [return]
- In fact when I say “cron” I was really thinking of a periodically-invoked cloud function. [return]
- Well, this is one of the many, many things involved in being senior/staff/principal. [return]